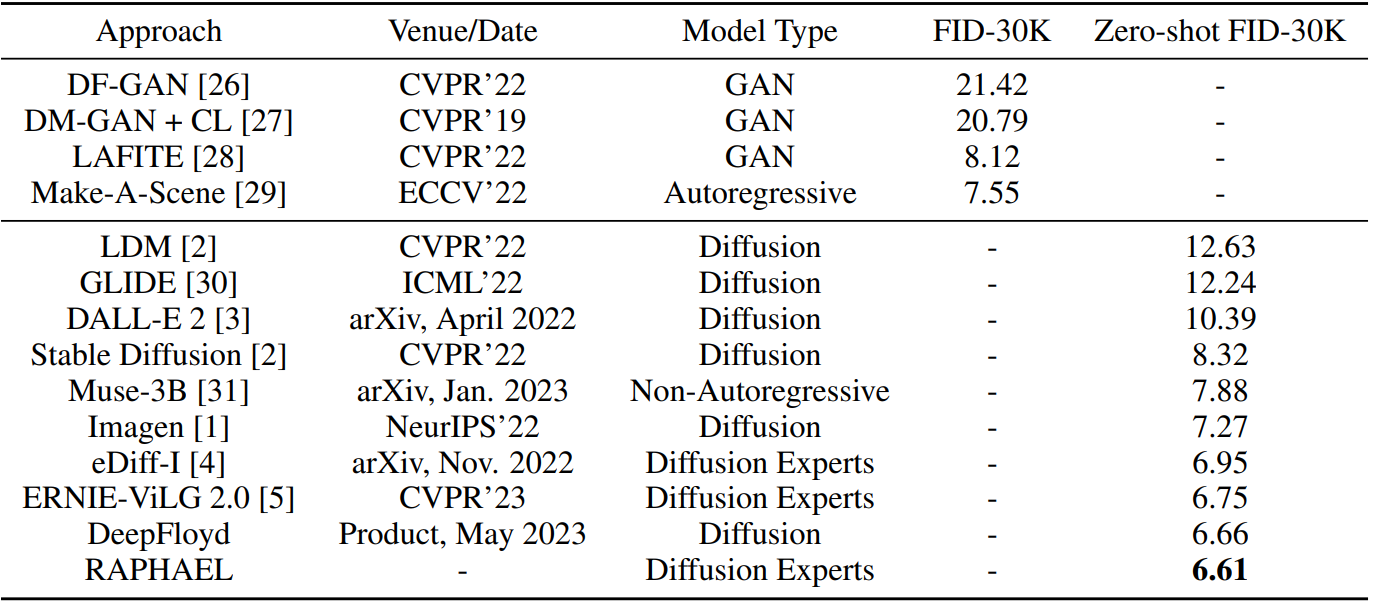
Comparison of presenting concepts

Comparisons of RAPHAEL with recent representative generators, Stable Diffusion XL, DeepFloyd, DALL-E 2,
and ERNIE-ViLG 2.0. They are given the same prompts, where the words that the human artists yearn to preserve within the
generated images are highlighted in red. We see that previous models often fail to preserve the desired concepts.
For example, only the RAPHAEL-generated images precisely reflect the prompts such as "pearl earring, Vermeer", "playing soccer", "five cars", "black
high-waisted trouser", "white hair, manga, moon", and "sign, RAPHAEL", while other models generate compromised results.
Comparison of aesthetics
Comparisons of RAPHAEL with DALL-E 2, Stable Diffusion XL (SD XL), ERNIE-ViLG 2.0, and DeepFloyd in a user study using the ViLG-300 benchmark. We report the user's
preference rates with 95% confidence intervals. We see that RAPHAEL can generate images with higher quality and better
conform to the prompts.
Efficient finetuning

Results with LoRA We use 32 images to finetune RAPHAEL and Stable Diffusion. The prompts are "A boy, flower/night/sword/none",
only RAPHAEL preserves the concepts in prompts while Stable Diffusion yields compromised results.
Prompts
Prompts generated by GPT-3.5 for Section 3.1 can be found here.
We use these templates to generate images and diffusion paths for each adjective, noun, and verb. The diffusion paths can be classified by XGBoost algorithm, and the accuracies reach more than 90%.